
 400-626-7377
400-626-7377
如何使用Spring Cloud微服务的分布式服务跟踪
随着业务的日趋复杂,系统的规模也会变得越来越复杂庞大,各个微服务之间的相互调用关系也会像蜘蛛网一样错综复杂。
通常由客户端发出请求后,后端微服务系统会通过许多不同的微服务调用共同完成最后请求结果的产生,在微服务架构系统中,几乎所有的客户端请求都会形成复杂的分布式服务链路脉络,任何超时延迟或者响应错误都有可能造成请求失败。这时通过全链路跟踪每个相关的微服务就变得尤为重要。
针对上面所述的分布式服务跟踪问题,Spring Cloud Sleuth提供了一套完整的解决方案。
让我们来分解如何为微服务系统搭建分布式服务跟踪的过程吧!
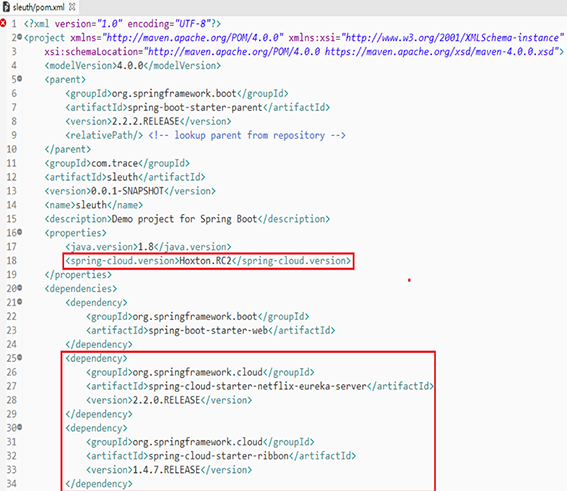
1.项目中的pom.xml配置文件中引入springcloud版本和eureka、ribbon依赖:
<spring-cloud.version>Hoxton.RC2</spring-cloud.version>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
<version>1.4.7.RELEASE</version>
</dependency>
完整pom.xml配置如下图所示:
2.修改application.yml设置端口和eureka:
# 注册服务
spring:
application:
name : sleuth1
sleuth:
sampler:
# 100%请求链路跟踪,一般在开发调试时使用
probability: 1
# 10%请求链路跟踪,一般在生成环境中使用
# probability: 0.1
# 设置tomcat端口
server:
port : 9900
eureka:
instance:
# 设置eureka服务注册中心IP地址
hostname : sleuth1
# 用IP地址形式获取注册中心地址
prefer-ip-address : true
client:
serviceUrl:
defaultZone : http://localhost:9002/eureka/
3.修改启动类
package com.trace.sleuth;
import org.jboss.logging.Logger;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.client.loadbalancer.LoadBalanced;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
import org.springframework.context.annotation.Bean;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
@RestController
@EnableEurekaServer
@EnableDiscoveryClient
@SpringBootApplication
public class SleuthApplication {
private final Logger logger=Logger.getLogger(getClass());
@Bean
@LoadBalanced
RestTemplate restTemplate() {
return new RestTemplate();
}
//通过/trace1接口调用sleuth2实例中的trace2接口
@RequestMapping(value="/trace1",method=RequestMethod.GET)
public String trace1() {
logger.info("call sleuth_trace1");
return restTemplate().getForEntity("http://sleuth2/trace2", String.class).getBody();
}
public static void main(String[] args) {
SpringApplication.run(SleuthApplication.class, args);
}
4. Maven clean,maven install,将打包的jar重名为sleuth9900.jar
5.关闭springcloud_Sleuthapp项目,将项目名称重名为springcloud_Sleuth1app项目,并复制一份再重名为springcloud_Sleuth2app项目
6.打开springcloud_Sleuth2app项目,修改applicaton.yml
# 注册服务
spring:
application:
name : sleuth2
# 设置tomcat端口
server:
port : 9901
eureka:
instance:
# 设置eureka服务注册中心IP地址
hostname : sleuth2
# 用IP地址形式获取注册中心地址
prefer-ip-address : true
client:
serviceUrl:
defaultZone : http://localhost:9002/eureka/
7. 打开并修改启动类
package com.trace.sleuth;
import org.jboss.logging.Logger;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
@RestController
@EnableEurekaServer
@EnableDiscoveryClient
@SpringBootApplication
public class SleuthApplication {
private final Logger logger=Logger.getLogger(getClass());
@RequestMapping(value="/trace2",method=RequestMethod.GET)
public String trace1() {
logger.info("call sleuth_trace2");
return " sleuth_trace2";
}
public static void main(String[] args) {
SpringApplication.run(SleuthApplication.class, args);
}
8.maven clean,maven install,将打包的jar重名为sleuth9901.jar
9.启动ribbon-consumer
10.通过以下命令启动sleuth1和sleuth2实例
java -jar c:/sleuth9900.jar
java -jar c:/sleuth9901.jar
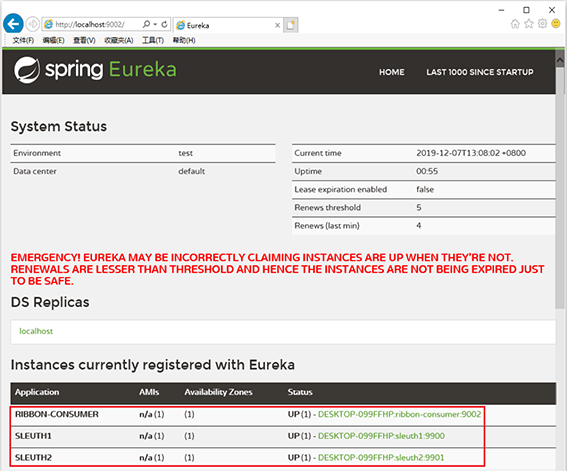
11. 查看http://localhost:9002,Ribbon-Consumer、Sleuth1和Sleuth2服务都已经分别在端口9002、9900和9901上启动了,如下图所示:
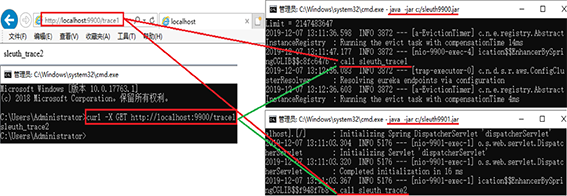
12.通过浏览器输入地址http://localhost:9900/trace1查看后台调用结果或通过命令curl -X GET http://localhost:9900/trace1查看后台调用结果,如下图所示:
13.在测试sleuth1和sleuth2服务启动成功后,我们停止sleuth1和sleuth2服务,并修改两个服务的pom.xml配置文件,分别加入sleuth依赖并重新打包运行
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
14.再次运行Ribbon-Consumer、Sleuth1和Sleuth2服务,通过浏览器输入地址http://localhost:9900/trace1查看后台调用结果或通过命令curl -X GET http://localhost:9900/trace1查看后台调用结果,如下图所示:
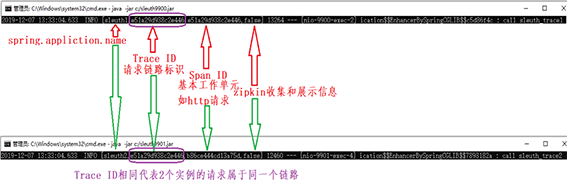
此时Sleuth1和Sleuth2服务将不是信息孤岛了,从图中可以看出spring.application.name分别是sleuth1服务名和sleuth2服务名,它们通过相同的Trace ID请求链路标识连接在了一起,图中随机标识号为e51a29d938c2e446,在这个相同的Trace ID请求链路标识后面紧跟着Span ID,分别标识sleuth1和sleuth2服务的分支ID,后面的false参数代表我们没有启动zipkin插件来收集和展示信息,在后续的学习中我们将会继续讲解如何装配zipkin,从而可以以直观的web端观察分布式服务的跟踪情况。
本文的最后还要提一下抽样的收集策略,因为在高并发的分布式系统运行时,大量的请求调用会产生海量的跟踪日志信息,这会造成服务器的大量日志存储开销如果。所以在Sleuth中采用了抽象收集的方式来为跟踪信息打上收集标记,可以大大降低存储开销的冗余。生产环境中的application.yml配置文件可做如下图所示的修改:
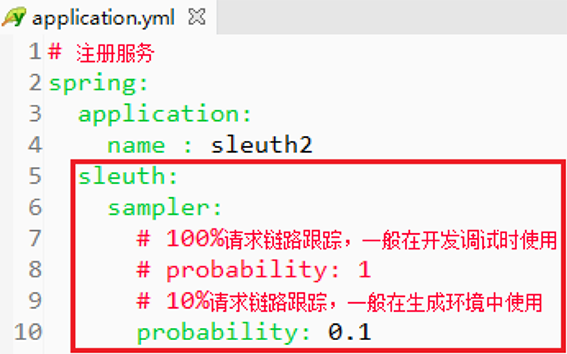
根据我们实际的跟踪数据量的需求,调整probability参数,从而减轻服务器的链路跟踪压力,从抽样数据标本中找到问题,而不是跟踪全部数据,大大提高服务器的使用效率。
通过本文的Spring Cloud微服务的分布式服务跟踪可以帮助读者了解在复杂的生产环境中如何跟踪多个连接微服务的情况,以最小数据量标本找到问题,中培的资深架构师会在课堂上给您更深入的微服务课程的讲解和实战案例的演示!
相关阅读
- 分布式和微服务,它们有什么区别?04-10
- 云原生中微服务的关键技术03-06
- 微服务和云原生架构是什么关系12-07
- 微服务为什么要用docker?11-09
- 微服务与SOA有哪些区别11-05
-

国家软考高级-系统规划与管理师
8月14-31日 在线咨询 -

国家软考高级-系统架构设计师
8月18-02日 在线咨询 -

容器+Kubernetes认证管理员(CKA)
8月20-30日 在线咨询 -

软件工程造价师认证
8月20-22日 在线咨询 -

CDSP数据安全认证专家
8月22-23日 在线咨询 -

人工智能实践项目案例分析与实战应用
8月24-27日 在线咨询 -

DAMA国际数据管理专业人士CDMP认证&DAMA中国数据治理工程师CDGA认证
8月25-27日 在线咨询 -

数据资产管理师CDAM认证
8月26-28日 在线咨询 -

国家注册信息安全专业人员CISP认证
8月27-31日 在线咨询 -

国家注册信息安全专业人员CISP-PTE渗透测试工程师认证
8月27-31日 在线咨询 -

ITSS-IT服务项目经理认证
8月27-29日 在线咨询 -

ITSS-IT服务工程师认证
8月27-28日 在线咨询 -

DAMA中国数据治理专家CDGP认证
8月28-30日 在线咨询 -

网络安全技术与攻防实战
8月28-30日 在线咨询 -

产品全生命周期管理运营与增长实战
8月28-30日 在线咨询
-
全国报名服务热线
 400-626-7377
400-626-7377
-
热门课程咨询
 在线咨询
在线咨询
-
微信公众号
 微信号:zpitedu
微信号:zpitedu
京ICP备13024721号-1
 京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377
京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377