
 400-626-7377
400-626-7377
如何构建一个Linux Shell(二)
在如何构建一个Linux Shell(一)中,我们构建了一个简单的Linux shell,该shell打印提示字符串,读取输入,然后将输入回显到屏幕上。现在这不是很令人印象深刻,不是吗?在如何构建一个Linux Shell(二)中,我们将更新代码,以使Shell能够解析和执行简单命令。首先让我们看一下什么是简单的命令。

什么是简单命令?
一个简单的命令 由单词列表组成,这些单词列表由空格字符(空格,制表符,换行符)分隔。第一个单词是命令名,并且是必需的(否则,shell将没有解析和执行命令!)。第二个和后续单词是可选的。如果存在,它们形成的论点,我们希望shell传递到执行的命令。
例如,以下命令: ls -l 由两个词组成: ls (命令名称),以及 -l(第一个也是唯一的参数)。同样,命令:gcc -o shell main.c prompt.c(在第一部分中,我们用它来编译我们的shell)由5个词组成:一个命令名和一个4个参数的列表。
为了能够执行简单的命令,我们的外壳程序需要执行以下步骤:
扫描输入,一次输入一个字符,以查找下一个标记。我们称此过程为词法扫描,而执行此任务的外壳部分称为词法扫描器,或简称为扫描器。
提取输入令牌。我们称这种标记化输入。
解析标记并创建抽象语法树或AST。Shell负责执行此操作的部分称为解析器。
执行AST。这是执行者的工作。
下图显示了Shell为了解析和执行命令而执行的步骤。您可以看到图中包含的步骤比上面列表中显示的步骤更多,这很好。随着外壳的增长和变得越来越复杂,我们将在需要时添加其他步骤。
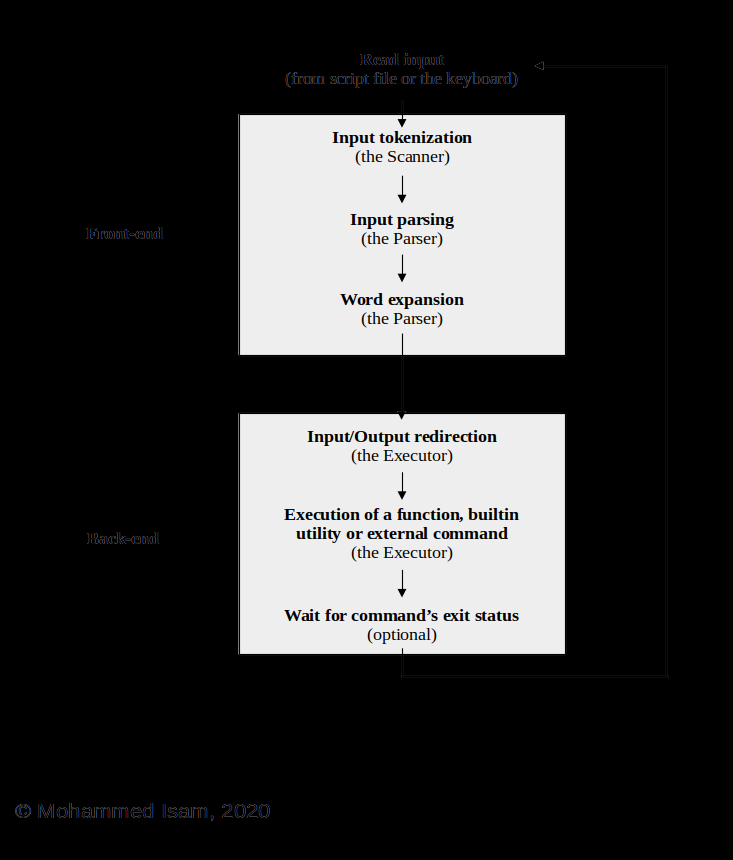
现在,让我们详细查看上述四个步骤,并查看在shell中实现这些功能所需的代码。
扫描输入
为了获得下一个令牌,我们需要能够一次扫描一个字符的输入,以便我们可以识别可以作为令牌一部分的字符和作为定界符的字符。甲分隔符是一个标记的令牌(以及可能的另一令牌的开始)的端部。通常,分隔符是空格字符(空格,制表符,换行符),但也可以包含其他字符,例如; 和 &。
通常,扫描输入意味着我们应该能够:
.从输入中检索下一个字符。
.返回我们读回的最后一个字符作为输入。
.前瞻(或窥视)以检查下一个字符,而无需实际检索它。
.跳过空白字符。
我们将在一分钟内定义执行所有这些任务的功能。但是首先,让我们谈谈抽象输入。
记住 read_cmd()函数,这是我们在本教程的第一部分中定义的?那就是我们用来读取用户输入并将其作为malloc的字符串。我们可以将此字符串直接传递给我们的扫描仪,但这会使扫描过程有点麻烦。特别是,扫描器很难记住它给我们的最后一个字符,以便它可以越过该字符并给我们后面的字符。
为了简化扫描仪的工作,我们通过将输入字符串作为 struct source_s 结构,我们将在源文件中定义 source.h。继续在源目录中创建该文件,然后在您喜欢的文本编辑器中将其打开并添加以下代码:
#ifndef SOURCE_H
#define SOURCE_H
#define EOF (-1)
#define ERRCHAR ( 0)
#define INIT_SRC_POS (-2)
struct source_s
{
char *buffer; /* the input text */
long bufsize; /* size of the input text */
long curpos; /* absolute char position in source */
};
char next_char(struct source_s *src);
void unget_char(struct source_s *src);
char peek_char(struct source_s *src);
void skip_white_spaces(struct source_s *src);
#endif
关注结构的定义,您可以看到 struct source_s 除了两个以外,还包含指向输入字符串的指针 long 包含有关字符串长度和我们当前在字符串中的位置(将从中获取下一个字符)的信息的字段。
现在创建另一个名为 source.c,您应在其中添加以下代码:
#include
#include "shell.h"
#include "source.h"
void unget_char(struct source_s *src)
{
if(src->curpos < 0)
{
return;
}
src->curpos--;
}
char next_char(struct source_s *src)
{
if(!src || !src->buffer)
{
errno = ENODATA;
return ERRCHAR;
}
char c1 = 0;
if(src->curpos == INIT_SRC_POS)
{
src->curpos = -1;
}
else
{
c1 = src->buffer[src->curpos];
}
if(++src->curpos >= src->bufsize)
{
src->curpos = src->bufsize;
return EOF;
}
return src->buffer[src->curpos];
}
char peek_char(struct source_s *src)
{
if(!src || !src->buffer)
{
errno = ENODATA;
return ERRCHAR;
}
long pos = src->curpos;
if(pos == INIT_SRC_POS)
{
pos++;
}
pos++;
if(pos >= src->bufsize)
{
return EOF;
}
return src->buffer[pos];
}
void skip_white_spaces(struct source_s *src)
{
char c;
if(!src || !src->buffer)
{
return;
}
while(((c = peek_char(src)) != EOF) && (c == ' ' || c == ' '))
{
next_char(src);
}
}
的 unget_char()函数将(我们从输入中检索到的)最后一个字符返回(或取消保护)到输入源。它只是通过操纵源结构的指针来做到这一点。在本系列后面的部分中,您将看到此功能的好处。
的 next_char() 函数返回输入的下一个字符并更新源指针,以便下一次调用 next_char()返回以下输入字符。当我们到达输入中的最后一个字符时,该函数将返回特殊字符EOF,我们在其中将其定义为-1 source.h 以上。
的 peek_char() 功能类似于 next_char()它返回输入的下一个字符。唯一的区别是peek_char() 不会更新源指针,因此下一次调用 next_char()返回我们刚刚偷看的相同输入字符。在本系列的后面部分,您将看到输入偷看的好处。
最后, skip_white_spaces()函数将跳过所有空格字符。这将在完成读取令牌后为我们提供帮助,并且在读取下一个令牌之前希望跳过定界符空白。
标记输入
现在我们已经有了扫描仪的功能,我们将使用这些功能来提取输入令牌。我们将首先定义一个新结构,该结构将用于表示令牌。
继续创建一个名为 scanner.h 在您的源目录中,然后将其打开并添加以下代码:
#ifndef SCANNER_H
#define SCANNER_H
struct token_s
{
struct source_s *src; /* source of input */
int text_len; /* length of token text */
char *text; /* token text */
};
/* the special EOF token, which indicates the end of input */
extern struct token_s eof_token;
struct token_s *tokenize(struct source_s *src);
void free_token(struct token_s *tok);
#endif
专注于结构定义, struct token_s 包含一个指向 struct source_s保留了我们的投入。该结构还包含一个指向令牌文本的指针,以及一个告诉我们该文本长度的字段(这样我们就无需重复调用strlen() 在令牌的文本上)。
接下来,我们将编写 tokenize()函数,它将从输入中检索下一个标记。我们还将编写一些帮助程序功能,以帮助我们使用输入令牌。
在源目录中,创建一个名为 scanner.c,然后输入以下代码:
#include
#include
#include
#include
#include "shell.h"
#include "scanner.h"
#include "source.h"
char *tok_buf = NULL;
int tok_bufsize = 0;
int tok_bufindex = -1;
/* special token to indicate end of input */
struct token_s eof_token =
{
.text_len = 0,
};
void add_to_buf(char c)
{
tok_buf[tok_bufindex++] = c;
if(tok_bufindex >= tok_bufsize)
{
char *tmp = realloc(tok_buf, tok_bufsize*2);
if(!tmp)
{
errno = ENOMEM;
return;
}
tok_buf = tmp;
tok_bufsize *= 2;
}
}
struct token_s *create_token(char *str)
{
struct token_s *tok = malloc(sizeof(struct token_s));
if(!tok)
{
return NULL;
}
memset(tok, 0, sizeof(struct token_s));
tok->text_len = strlen(str);
char *nstr = malloc(tok->text_len+1);
if(!nstr)
{
free(tok);
return NULL;
}
strcpy(nstr, str);
tok->text = nstr;
return tok;
}
void free_token(struct token_s *tok)
{
if(tok->text)
{
free(tok->text);
}
free(tok);
}
struct token_s *tokenize(struct source_s *src)
{
int endloop = 0;
if(!src || !src->buffer || !src->bufsize)
{
errno = ENODATA;
return &eof_token;
}
if(!tok_buf)
{
tok_bufsize = 1024;
tok_buf = malloc(tok_bufsize);
if(!tok_buf)
{
errno = ENOMEM;
return &eof_token;
}
}
tok_bufindex = 0;
tok_buf[0] = '�';
char nc = next_char(src);
if(nc == ERRCHAR || nc == EOF)
{
return &eof_token;
}
do
{
switch(nc)
{
case ' ':
case ' ':
if(tok_bufindex > 0)
{
endloop = 1;
}
break;
case ' ':
if(tok_bufindex > 0)
{
unget_char(src);
}
else
{
add_to_buf(nc);
}
endloop = 1;
break;
default:
add_to_buf(nc);
break;
}
if(endloop)
{
break;
}
} while((nc = next_char(src)) != EOF);
if(tok_bufindex == 0)
{
return &eof_token;
}
if(tok_bufindex >= tok_bufsize)
{
tok_bufindex--;
}
tok_buf[tok_bufindex] = '�';
struct token_s *tok = create_token(tok_buf);
if(!tok)
{
fprintf(stderr, "error: failed to alloc buffer: %s ", strerror(errno));
return &eof_token;
}
tok->src = src;
return tok;
}
我们在此文件中定义的全局变量用于以下目的:
.tok_buf 是指向我们将在其中存储当前令牌的缓冲区的指针。
.tok_bufsize 是我们分配给缓冲区的字节数。
.tok_bufindex 是当前缓冲区的索引(即它告诉我们缓冲区中下一个输入字符的添加位置)。
.eof_token是一个特殊的令牌,我们将用它来表示文件/输入的结尾(EOF)。
现在让我们看一下在此文件中定义的功能。
的 add_to_buf()函数将单个字符添加到令牌缓冲区。如果缓冲区已满,则函数将对其进行扩展。
的 create_token() 函数接受一个字符串并将其转换为 struct token_s结构体。它负责为令牌的结构和文本分配内存,并填充结构的成员字段。
的 free_token() 函数释放令牌结构使用的内存以及用于存储令牌文本的内存。
的 tokenize()函数是我们词法扫描器的心脏和灵魂,并且函数的代码相当简单。首先,为令牌缓冲区分配内存(如果尚未完成),然后初始化令牌缓冲区和源指针。然后调用next_char()检索下一个输入字符。当我们到达输入结尾时,tokenize() 返回特殊 eof_token,表示输入结束。
然后,该函数循环读取一次输入的字符。如果遇到空白字符,它将检查令牌缓冲区以查看其是否为空。如果缓冲区不为空,则定界当前令牌并中断循环。否则,我们将跳过空格字符,并移至下一个标记的开头。
获得令牌后, tokenize() 来电 create_token(),并向其传递令牌文本(我们将其存储在缓冲区中)。令牌文本将转换为令牌结构,tokenize() 然后返回到呼叫者。
我们确实在这部分上取得了很大的进步,但是我们的shell仍未准备好解析和执行命令。因此,我们现在不会编译该shell。在实现解析器和执行器之后,我们的下一个编译将在第三部分的结尾。想了解更多关于Linux的信息,请继续关注中培伟业吧。
相关阅读
- IT运维领域权威证书:ITSS认证12-22
- 分析ITIL4和IT运维的关系11-13
- IT运维考ITSS服务工程师证书好吗?08-14
- 这4本证书火了!IT运维从业人员必备07-27
- IT运维好学吗?难度大吗?07-10





-
全国报名服务热线
 400-626-7377
400-626-7377
-
热门课程咨询
 在线咨询
在线咨询
-
微信公众号
 微信号:zpitedu
微信号:zpitedu
京ICP备13024721号-1
 京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377
京公网安备11010602007294号 增值电信业务经营许可证:京B2-20201348 全国统一报名专线:400-626-7377