 400-626-7377
400-626-7377
400-626-7377

AI大模型的全称是"Artificial Intelligence Large-scale Model",即"人工智能大规模模型"。这个术语通常用来描述具有巨大规模参数和训练数据的机器学习模型,如Transformer、GPT、BERT等。大模型通常由深度神经网络构建,通过在大规模数据上进行预训练(Pre-training)和微调(Fine-tuning),学习到丰富的特征表示和知识。
AI大模型最显著的优势之一是处理海量数据的能力。AI大模型通过高效的数据处理技术,能够快速地分析和处理大规模数据集,为各种应用场景提供有力支持。
AI大模型的另一个优势是优化算法的能力。通过深度学习和强化学习等技术,AI大模型能够不断地自我学习和改进,提高算法的准确性和效率。
AI大模型的第三个优势是提高机器学习效率。通过采用分布式计算和并行处理等技术,AI大模型能够在短时间内完成大规模的机器学习任务,加速人工智能的开发和应用进程。
人工智能属于新兴产业,意识到其将成为下个风口并入行的人并不多
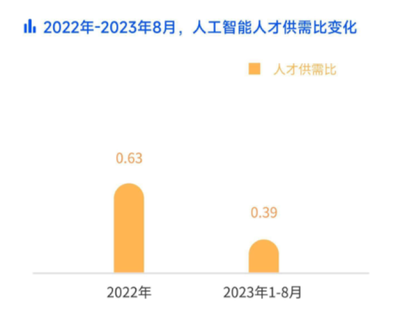
据相关数据显示:
· 2022年人工智能人才供需比为0.63
· 2023年人工智能人才供需比下降到了0.39
这意味着人工智能行业目前是5个岗位抢2个人才
Levels.fyi发布了2024年第一季度薪酬报告,中国AI工程师薪资排名12名
根据Levels.fyi的官方统计,中国AI工程师的薪资范围大致在6.4-13.4万美元(约人民币46.3-97万元)

政府工作报告首提“人工智能+”,多位委员代表也纷纷围绕AI建言献策
,涵盖AI产业、AI教育、AI安全等方面,共同探讨人工智能在中国
未来的发展方向和战略布局

· 2017年发布的《新一代人工智能发展规划》
· 2022 年印发《关于加快场景创新以人工智能高水平应用促进经济高质量发展的指导意见》
· 2024年,人工智能+更是被写入了《政府工作报告》
· 各地方政府出台相关支持政策,加快大模型产业的持续发展
根据国家信息中心与浪潮信息联合发布的《智能计算中心创新发展指南》,目前全国有超过30个城市正在建设或提出建设智算中心,“十四五”期间,对智算中心的投资可带动人工智能核心产业增长约2.9-3.4倍
AI大模型的应用,已经涉及到金融、政务、教育、医疗、制造、娱乐等多个领域,为各行各业带来了新的机遇
· 国际数据公司 IDC 预测,全球 AI 计算市场规模将从 2022 年的 195.0 亿美元增长到 2026 年的 346.6 亿美元
· IDC 预计中国人工智能市场规模在 2023 年将超过 147 亿美元,到 2026 年这一规模将超过 264 亿美元
· 大模型理论知识
· 自注意力机制、Transformer模型、BERT模型
· LLM应用程序技术栈和提示词工程Prompt Enginerring
· 掌握DeepSeek与ChatGPT原理与实战
· 了解国产大模型ChatGLM
· 了解视觉大模型技术优势
· 掌握语言理解与字幕生成及其应用
· 掌握图像生成和应用实操
· 应用场景与潜力分析
· 大模型企业商用项目实战
· 大模型的详细介绍、核心技术、部署等相关理论知识
· 自注意力机制、Transformer模型、BERT模型
· Embedding、LLM
· DeepSeek、Chat GPT4
· LangChain、LangGraph
· 大模型微调、AI-Agent
· 基本问答系统的代码实现
· 深入阅读理解的代码实现
· 段落相关性代码实现
· LLM大模型的使用
· Prompts的设计和使用
· 动手实现知识问答机器人
· LangChain文本摘要
· PDF文本阅读问答
· Embedding结果的可视化展示与结果分析实战
· 基于DeepSeek的企业级实战案例
· 基于GLM4的长文本读取与优化
· 海量文本的Embedding高效匹配
· AI-Agent 构建可发布的智能客服系统
DeepSeek平台接入与认证
DeepSeek-V3、DeepSeek-R1、DeepEP
DeepSeep核心功能调用方法
DeepSeek联网搜索与扩展
DeepSeek计费与优化建议
Llama_Factory 微调实战
掌握如何科学构建训练数据
微调常见方式介绍
Unsloth微调平台介绍
Llama3开源大模型的微调与使用
AI-Agent 构建可发布的智能客服系统
AutoGPT基本原理、安装与环境配置与实战
如果你正在从事人工智能、机器学习、数据分析等相关领域的工作,或者想要进入这些领域,那么学习AI大模型开发将会对你的职业发展有很大的帮助
这类专业人士可以通过学习AI大模型开发课程来提升团队的研发效率,了解大模型如何影响软件架构,并掌握基于大语言模型的全新开发范式
如果你对人工智能、机器学习等领域有浓厚的兴趣,想要深入了解并掌握相关技能,并有一定的软件开发基础
1、初探大模型:起源与发展
2、GPT模型家族:从始至今
3、大模型_GPT_ChatGPT的对比介绍
4、大模型实战-大模型2种学习路线的讲解
5、 大模型最核心的三项技术:模型、微调和开发框架
6、 0penAl GPT系列在线大模型技术生态
7、0penAl文本模型A、B、C、D四大模型引擎简介
8、0penAl语音模型Whisper与图像型DALL·E模型介绍
9、最强Embedding大模型text-embedding-ada模型介绍
10、全球开源大模型性能评估榜单
11、中文大模型生态介绍与GLM 130B模型介绍
12、ChatGLM模型介绍与部署门槛
13、ChatGLM开源生态:微调、多模态,WebUI等项目简介
RNN-LSTM-GRU等基本概念
编码器、解码器
自注意力机制详解
Transformer
Mask Multi-Head Attention
位置编码
特定于任务的输入转换
无监督预训练、有监督 Fine-tuning
BERT思路的理解
BERT模型下游任务的网络层设计
BERT的训练
HuggingFace中BERT模型的推断
基于上下文的学习
代码和案例实践:
基本问答系统的代码实现
深入阅读理解的代码实现
段落相关性代码实现
大模型技术浪潮下的Embedding技术定位
Embedding技术入门介绍
从Ono-hot到Embedding
Embedding文本衡量与相似度计算
OpenAl Embedding模型与开源Embedding框架
两代OpenAl Embedding模型介绍
text-embedding-ada-002模型调用方法详解
text-embedding-ada-002模型参数详解与优化策略
借助Embedding进行特征编码
Embedding结果的可视化展示与结果分析
【实战】借助Embedding特征编码完成有监督预测
【实战】借助Embedding进行推荐系统冷启动
【实战】借助Embedding进行零样本分类与文本搜索
Embedding模型结构微调优化
借助CNN进行Embedding结果优化
【企业级实战】海量文本的Embedding高效匹配
设计模式:上下文学习
数据预处理/嵌入
提示构建/检索
提示执行/推理
数据预处理/嵌入
Weaviate、Vespa 和 Qdrant等开源系统
Chroma 和 Faiss 等本地向量管理库
pgvector 等OLTP 扩展
提示构建/检索
提示执行/推理
新兴的大语言(LLM)技术栈
数据预处理管道(data preprocessing pipeline)
嵌入终端(embeddings endpoint )+向量存储(vector store)
LLM 终端(LLM endpoints)
LLM 编程框架(LLM programming framework)
LangChain的主要功能及模块
Prompts: 这包括提示管理、提示优化和提示序列化。
LLMs: 这包括所有LLMs的通用接口,以及常用的LLMs工具。
Document Loaders: 这包括加载文档的标准接口,以及与各种文本数据源的集成。
Utils: 语言模型在与其他知识或计算源的交互
Python REPLs、嵌入、搜索引擎等
LangChain提供的常用工具
Indexes:语言模型结合自定义文本数据
Agents:动作执行、观测结果
LangChain的代理标准接口、可供选择的代理、端到端代理示例
Chat:Chat模型处理消息
代码和案例实践:
LLM大模型的使用
Prompts的设计和使用
新一代DeepSeek模型API调用
DeepSeek开放平台使用方法与APIKey申请
DeepSeek-V3、DeepSeek-R1、DeepEP介绍
DeepSeek在线知识库使用及模型计费说明
DeepSeek模型SDK调用与三种运行方法
DeepSeek调用函数全参数详解
DeepSeek Message消息格式与身份设置方法
DeepSeek tools外部工具调用方法
DeepSeek Function calling函数封装12GLM4接入在线知识库retrieval流程
DeepSeek接入互联网web_search方法
【实战】基于DeepSeek打造自动数据分析Agent
【实战】基于DeepSeek的自然语言编程实战
【实战】基于DeepSeek Function call的用户意图识别
【实战】基于GLM4的长文本读取与优化
构建垂直领域大模型的通用思路和方法
(1) 大模型+知识库
(2) PEFT(参数高效的微调)
(3) 全量微调
(4) 从预训练开始定制
LangChain介绍
LangChain模块学习-LLMs 和 Prompts
LangChain之Chains模块
LangChain之Agents模块
LangChain之Callback模块
Embedding嵌入
自定义知识库
知识冲突的处理方式
向量化计算可采用的方式
文档加载器模块
向量数据库问答的设计
Lanchain竞品调研和分析
Dust.tt/Semantic-kernel/Fixie.ai/Cognosis/GPT-Index
LlamaIndex介绍
LlamaIndex索引
动手实现知识问答系统
代码和案例实践:
动手实现知识问答机器人
LangChain文本摘要
PDF文本阅读问答
LangGraph 构建自适应RAG
1.LangGraph 应用场景、核心功能、特点
2.基础概念:节点、边、图等
3.LangGraph 的系统架构
4.数据模型和存储机制
5.基本数据查询与操作
6.高级查询:路径查询、模式匹配
7.使用本地LLM自适应RAG
8.代理RAG与纠正(CRAG)
1. 各种模型文件介绍
2. 模型的推理、量化介绍与实现
3. Modelscope、Hugging Face简单介绍与使用
4. 大模型管理底座Ollama介绍
5. Ollama + lLama 部署开源大模型
6. Open WebUI发布与调用大模型
7. API Key获取与 Llama微调实现
Llama_Factory 微调实战
1. 提升模型性能方式介绍:Prompt、知识库、微调
2. 如何科学构建训练数据(基础与专业数据混合训练)
3. 微调常见方式介绍:微调、偏好对齐、蒸馏、奖励模型
4. Llama3 模型架构与调用申请
5. 数据上传与任务创建(job)
6. 训练集与测试集拆分与模型评估
7. Unsloth微调平台介绍
8. Llama3开源大模型的微调与使用
9. 模型的评估策略
AI-Agent 构建可发布的智能客服系统
1. 智能体介绍与AutoGPT基本原理
2. AutoGPT安装与环境配置
3. 实战体验:AutoGPT实现数据爬取、清洗、保存
4. 创建各种场景的AutoGPT
5. 内容创建
6. 客服服务
7. 数据分析
8. 代码编写
9. 创建应用程序







