 400-626-7377
400-626-7377
400-626-7377











数据挖掘的目的是更好地帮助业务,所以要首先从商业的角度理解项目需求,在此基础上再对数据挖掘的目标进行定义
模型的作用是找到有价值的数据,获得的数据需要进行可视化,转化成用户可以使用的方式,同时要持续监控和维护
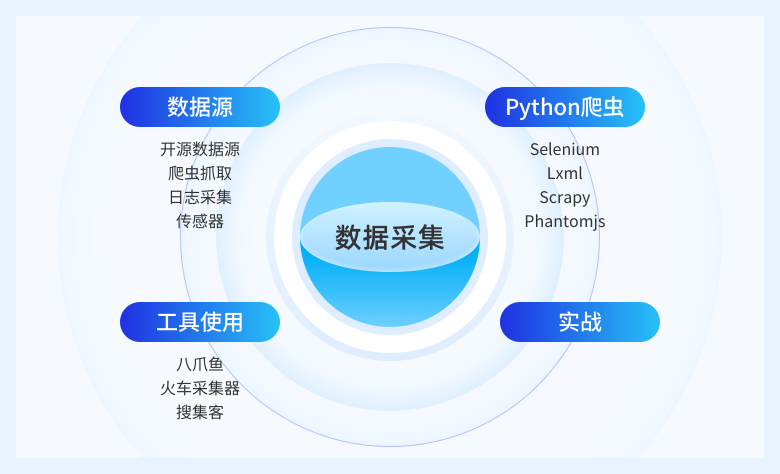
尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等,这有助于对收集到的数据有初步的认知
对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的商业目标
开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作
选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果



资深Linux运维行业大牛倾力打造
为您的学习保驾护航

理论结合实战
培养您独立思考和解决问题的能力

课程紧跟行业趋势
让您学有所用,用有所成
19年的行业积累
完善的高效培训体系

面授、电脑端、APP端融合
反复学反复练
讲解Python背景、国内发展状况、基础语法、数据结构及绘图操作等内容。特别针对向量计算这块,着重介绍Python在这方面的优势及用法。
讲解统计分析基础,包括统计学基本概念,假设检验,置信区间等基础,并结合数据案例说明其使用场景和运用方法。介绍数据分析流程和常见分析思路,并结合案例进行讲解。
从数据接入、数据统计、数据转换等几个方面进行讲解。数据接入包含接入MySQL、Oracle、Hadoop等常见数据库操作;数据统计包含Pandas包的具体用法和讲解;数据转换包含对数据集的关联、合并、重塑等操作。此外,针对海量数据的情况下,介绍在Spark平台上的数据处理技术,并结合真实环境进行操作讲解。
讲解数据挖掘基本概念,细致讲解业务理解、数据理解、数据准备、建立模型、模型评估、模型部署各环节的工作内容及相关技术;结合业界经典场景,讲解数据挖掘的实施流程和方法体系。
细致讲解抽样、分区、样本平衡、特征选择、训练模型、评估模型等数据挖掘核心技术原理,并结合案例讲解其具体实现和用法。尤其针对样本平衡,重点讲解人工合成、代价敏感等算法;针对特征选择,重点讲解特征选择的核心思路,并结合Python进行案例演示。
降维是大数据分析非常重要的算法,它可以在降低极少信息量的情况下,极大地缩小数据规模。主要讲解主成分、LDA以及t-SNE原理,并结合案例进行Python实现。特别地,针对海量数据情况下的应用场景,讲解实现思路和Python案例。
决策树是非常经典的算法,一般常见于小数据的挖掘。由于决策树具有极强的可解释性,针对海量数据仍然是非常重要的实用价值。主要讲解ID3、C4.5、C5.0以及CART决策树算法的实现原理,并结合案例进行Python实现。
实战部分:基于好莱坞百万级的影评数据,对数据进行建模、清洗、透视表操作。然后根据用户画像分析不同的用户喜好通过机器学习算法对不同性别、年龄阶段的用户进行定制化的电影推荐,最后把推荐的电影进行可视化的展示操作
大数据分析技术可以帮助我们去发现、解决一些业务问题,然而如何去判断我们的改进是否生效,是否在业务指标上呈现过一定的因果逻辑,则是一个重要问题和分析方向。本节主要介绍因果推理算法,包括贝叶斯推理、状态空间模型以及CausalImpact工具等内容,并结合案例进行Python实现。
对于大数据的建模任务,我们可以基于深度学习来实现,不仅能够针对海量数据进行建模,其效果也非常不错。本节主要讲解深度学习的发展历程,DBN、DNN等经典深度学习算法,深度学习优化算法以及一些技巧。同时,介绍Keras、OpenCV库的使用方法,并结合案例进行Python实现。
实战部分:基于YOLO面部模型,完成对图片和视频的人脸识别,实战中会讲解YOLO的重要类和函数。主要内容包括YOLO库的安装和部署、图像增强、像素操作、图形分析等各种技术,并且详细介绍了如何处理来自文件或摄像机的视频,以及如何检测和跟踪移动对象。
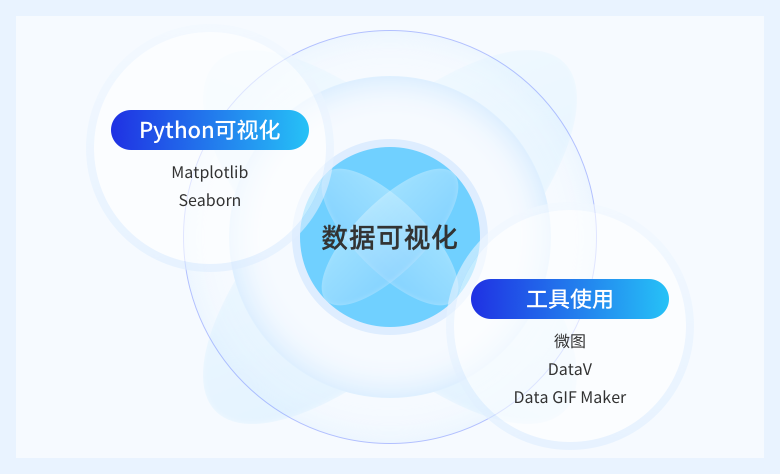
数据可视化是大数据分析的重要手段,通过合理地使用图表,不仅可以简洁地表达数据的含义,高效地发现问题,还可以为报告的编写以及数据分析web应用增色不少。本节主要讲解常用的数据分析图表及其使用场景,介绍数据可视化的方法论,避免生搬硬套的使用图表,针对不同的业务场景和需求,合理选择可视化方法。介绍的工具不限于matplotlib、pycha、pyecharts、ggplot、Bokeh、HoloViews、mpld3、plotly、pygal等常用可视化库。
数据分析报告在大数据分析过程中具有重要价值,它体现了大数据分析的目的、过程和结果,以及对发现问题的解读、改进方案等等,本节主要讲解使用Notebook编写数据分析报告的具体方法,以及编写数据分析报告的方法论,并结合案例讲解其用法。
Seaborn是一款不错的可视化框架,它和 Pandas一样是建立在 Matplotlib 之上的。可以基于Seaborn快速开发一个轻量级的数据分析web应用。在网页中嵌入图表、数据以及分析的算法,非常适合打造企业内部的敏捷数据分析工具集。本节主要介绍Pie、Scatter、Radar等等各种可视化解决方案,同时讲解一个用Seaborn实现数据分析功能(兼图表)的实际案例,搭建服务器,在企业内部实现轻量级数据分析应用。
DeepSeek作为一款全能型AI助手,致力于提升职场工作效率。通过其核心功能,DeepSeek能帮助职场人士自动化处理会议纪要、合同提取、PPT制作等日常任务,从而节省时间并提高工作效率。它还能够通过精准的数据分析为决策提供洞察,并激发创意生成内容,如短视频脚本和文案,彻底打破传统内容生成的思维模式。
Dify是一款低代码应用开发平台,通过与DeepSeek R1的无缝集成,能够快速构建定制化的智能应用。利用Dify,用户可以轻松实现工作流自动化和智能增强,进一步提升业务效率。DeepSeek R1在客服自动应答、智能文档处理、数据分析等多个场景中得到广泛应用,通过优化工作流,简化多步骤任务,提高整体业务流程的自动化水平,从而实现职场赋能和创新驱动。
